Latency Matters: Real-Time Action Forecasting Transformer
Bigger Models are NOT Necessarily Better
In this paper, we propose a new real-time setting for evaluating action forecasting networks where bigger models do not necessarily achieve a better performance. Current state-of-the-art methods trend towards increasing model size for higher fidelity forecasts, ignoring the cost of increased latency. The new latency-aware real-time setting better mimics practical deployment settings for embodied forecasting systems, paving the path for the development of latency-aware forecasting models in the future.
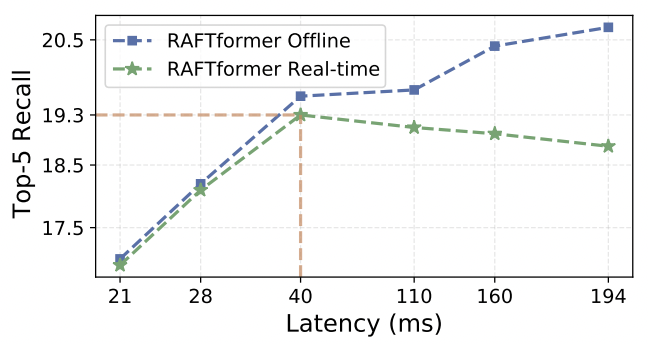
The graph above shows a clear trade-off between latency and high-fidelity forecasts in the real-time evaluation setting. We observe that bigger models continue to perform better in latency agnostic offline settings. However, in the real-time setting, models with very high latency (big models) gradually perform worse due to limited access to the most recent video data.
Video
Overview of Real-Time Evaluation Setting
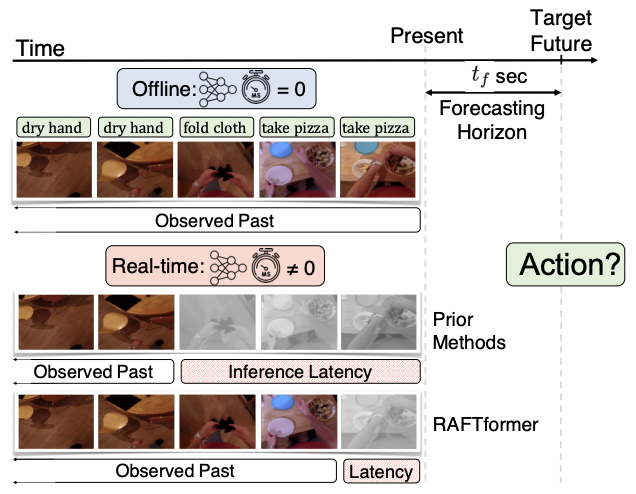
This diagram details the difference between offline and real-time evaluation. During offline evaluation, inference latency is assumed to be zero, allowing predictions to be made at any time step using all prior frames up to the forecasting horizon. During real-time evaluation, the nonzero inference latency of the model must be accounted for. In this setting, predictions must be made using frames further in the past. A model with reduced latency is able to leverage significantly more recent frames than prior methods, leading to more accurate predictions.
We present RAFTformer, a real-time action forecasting transformer for latency-aware real-world action forecasting. RAFTformer is a two-stage fully transformer based architecture comprising of a video transformer backbone that operates on high resolution, short-range clips, and a head transformer encoder that temporally aggregates information from multiple short-range clips to span a long-term horizon. Additionally, we propose a novel self-supervised shuffled causal masking scheme as a model level augmentation to improve forecasting fidelity. Finally, we also propose a novel real-time evaluation setting for action forecasting that directly couples model inference latency to overall forecasting performance and brings forth a hitherto overlooked trade-off between latency and action forecasting performance. Our parsimonious network design facilitates RAFTformer inference latency to be 9x smaller than prior works at the same forecasting accuracy. Owing to its two-staged design, RAFTformer uses 94% less training compute and 90% lesser training parameters to outperform prior state-of-the-art baselines by 4.9 points on EGTEA Gaze+ and by 1.4 points on EPIC-Kitchens100 validation set, as measured by Top-5 recall (T5R) in the offline setting. In the real-time setting, RAFTformer outperforms prior works by an even greater margin of up to 4.4 T5R points on the EPIC-Kitchens-100 dataset.
We also introduce RAFTformer, an architecture that beats prior state-of-the-art action forecasting methods with a huge reduction in latency. Please see the paper for further details.
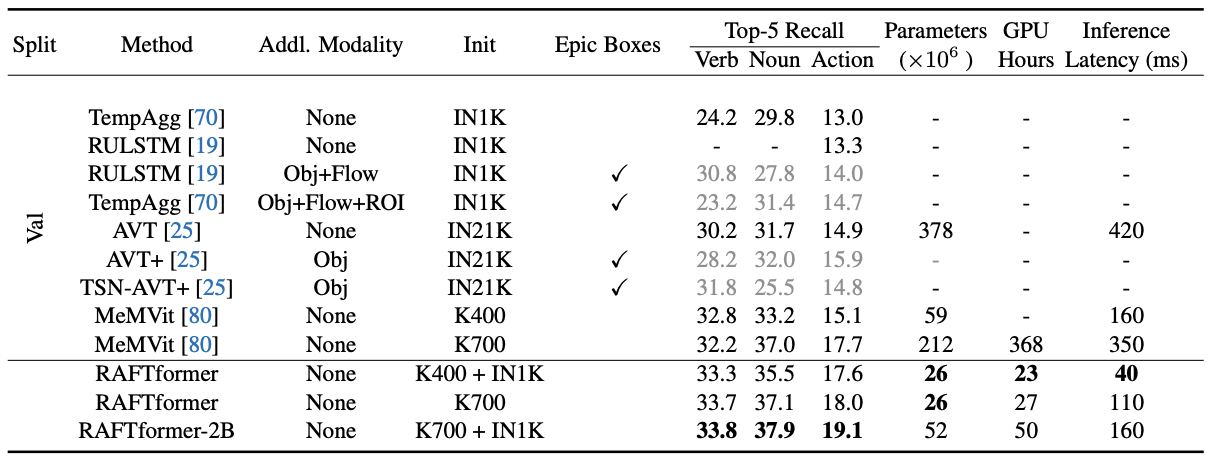
The above table displays offline evaluation results on the EPIC-Kitchens-100 dataset for a one second forecasting horizon. RAFTformer matches previous state-of-the-art models in action T5R while reducing latency by 9x, parameters by 8x, and training time in GPU hours by 94%. RAFTformer-2B, which combines two separate RAFTformer models to train a two-backbone model, achieves state-of-the-art results by a 1.4% T5R increase.
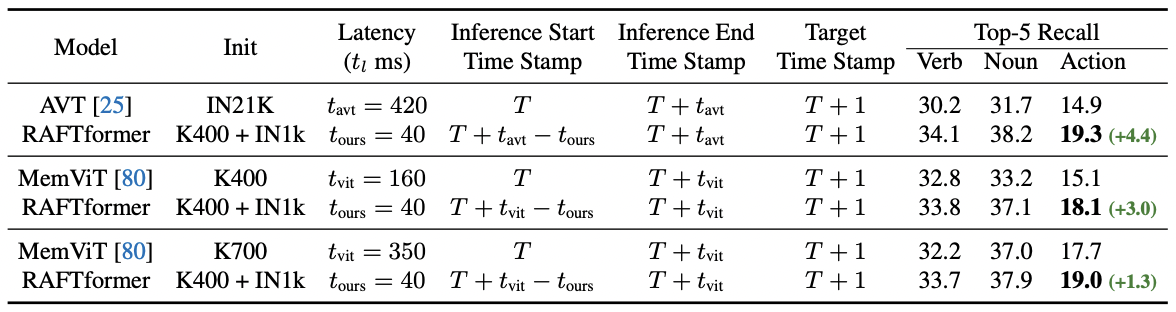
This table displays real-time evaluation results on the EPIC-Kitchens-55 dataset. Each comparison is performed between a pair of models with their inference start times adjusted to account for latency such that they produce the forecasting output simultaneously. In this setting, faster models can pragmatically utilize recent frames while slower models must rely on higher fidelity prediction from older frames. We observe that RAFTformer outperforms prior methods by an even larger margin in the real-time evaluation setting than in the offline setting.
BibTeX
@inproceedings{girase2023latency,
title = {Latency Matters: Real-Time Action Forecasting Transformer},
author = {Girase, Harshayu and Agarwal, Nakul and Choi, Chiho and Mangalam, Karttikeya},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {18759--18769},
year = {2023}
}